
Get NPTEL Machine Learning Week 6 answers at nptel.answergpt.in. Our expert-verified solutions help you understand key concepts, simplify complex topics and enhance your assignment performance with accuracy and confidence.
📌 Subject: Machine Learning
📌 Week: 6
📌 Session: NPTEL 2025
📌 Course Link: NPTEL Machine Learning
📌 Reliability: Expert-reviewed answers
We recommend using these answers as a reference to verify your solutions. For complete, detailed solutions for all weeks, visit – [Week 1-12] NPTEL Introduction to Machine Learning Assignment Answers 2025.
🚀 Stay ahead in your NPTEL journey with updated solutions every week!
| Week-by-Week NPTEL Machine Learning Assignments in One Place |
|---|
| Machine Learning Week 1 Answers |
| Machine Learning Week 2 Answers |
| Machine Learning Week 3 Answers |
| Machine Learning Week 4 Answers |
| Machine Learning Week 5 Answers |
| Machine Learning Week 6 Answers |
| Machine Learning Week 7 Answers |
| Machine Learning Week 8 Answers |
| Machine Learning Week 9 Answers |
| Machine Learning Week 10 Answers |
| Machine Learning Week 11 Answers |
| Machine Learning Week 12 Answers |
NPTEL Introduction to Machine Learning Week 6 Assignment Answers 2025
1. Statement: Decision Tree is an unsupervised learning algorithm.
Reason: The splitting criterion use only the features of the data to calculate their respective measures
- Statement is True. Reason is True.
- Statement is True. Reason is False
- Statement is False. Reason is True
- Statement is False. Reason is False
Answer :- For Answers Click Here
2. Increasing the pruning strength in a decision tree by reducing the maximum depth:
- Will always result in improved validation accuracy.
- Will lead to more overfitting
- Might lead to underfitting if set too aggressively
- Will have no impact on the tree’s performance.
- Will eliminate the need for validation data.
Answer :-
3. What is a common indicator of overfitting in a decision tree?
- The training accuracy is high while the validation accuracy is low.
- The tree is shallow.
- The tree has only a few leaf nodes.
- The tree’s depth matches the number of attributes in the dataset.
- The tree’s predictions are consistently biased.
Answer :-
4. Consider the following statements:
Statement 1: Decision Trees are linear non-parametric models.
Statement 2: A decision tree may be used to explain the complex function learned by a neural network.
- Both the statements are True.
- Statement 1 is True, but Statement 2 is False.
- Statement 1 is False, but Statement 2 is True.
- Both the statements are False.
Answer :- For Answers Click Here
5. Entropy for a 50-50 split between two classes is:
- 0
- 0.5
- 1
- None of the above
Answer :-
6. Consider a dataset with only one attribute(categorical). Suppose, there are 10 unordered values in this attribute, how many possible combinations are needed to find the best split-point for building the decision tree classifier?
- 1024
- 511
- 1023
- 512
Answer :-
7. Consider the following dataset:
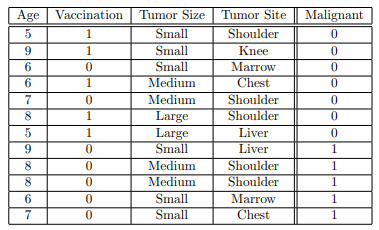
What is the initial entropy of Malignant?
- 0.543
- 0.9798
- 0.8732
- 1
Answer :-
8. For the same dataset, what is the info gain of Vaccination?
- 0.4763
- 0.2102
- 0.1134
- 0.9355
Answer :- For Answers Click Here
Introduction to Machine Learning Week 6 NPTEL Assignment Answers 2024
1. Entropy for a 90-10 split between two classes is:
- 0.469
- 0.195
- 0.204
- None of the above
Answer :- a
2. Consider a dataset with only one attribute(categorical). Suppose, there are 8 unordered values in this attribute, how many possible combinations are needed to find the best split-point for building the decision tree classifier?
- 511
- 1023
- 512
- 127
Answer :- d
3. Having built a decision tree, we are using reduced error pruning to reduce the size of the tree. We select a node to collapse. For this particular node, on the left branch, there are three training data points with the following outputs: 5, 7, 9.6, and for the right branch, there are four training data points with the following outputs: 8.7, 9.8, 10.5, 11. The average value of the outputs of data points denotes the response of a branch. The original responses for data points along the two branches (left & right respectively) were response−left and, response−right and the new response after collapsing the node is response−new. What are the values for response−left, response−right and response−new (numbers in the option are given in the same order)?
- 9.6, 11, 10.4
- 7.2; 10; 8.8
- 5, 10.5, 15
- depends on the tree height.
Answer :- b
4. Which of the following is a good strategy for reducing the variance in a decision tree?
- If improvement of taking any split is very small, don’t make a split. (Early Stopping)
- Stop splitting a leaf when the number of points is less than a set threshold K.
- Stop splitting all leaves in the decision tree when any one leaf has less than a set threshold K points.
- None of the Above.
Answer :- b
5. Which of the following statements about multiway splits in decision trees with categorical features is correct?
- They always result in deeper trees compared to binary splits
- They always provide better interpretability than binary splits
- They can lead to overfitting when dealing with high-cardinality categorical features
- They are computationally less expensive than binary splits for all categorical features
Answer :- c
6. Which of the following statements about imputation in data preprocessing is most accurate?
- Mean imputation is always the best method for handling missing numerical data
- Imputation should always be performed after splitting the data into training and test sets
- Missing data is best handled by simply removing all rows with any missing values
- Multiple imputation typically produces less biased estimates than single imputation methods
Answer :- d
7. Consider the following dataset:
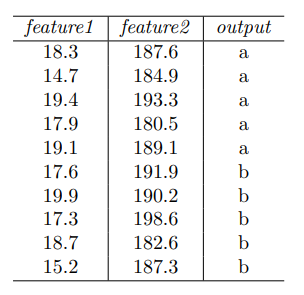
Which among the following split-points for feature2 would give the best split according to the misclassification error?
- 186.5
- 188.6
- 189.2
- 198.1
Answer :- c
Conclusion:
In this article, we have uploaded the Introduction to Machine Learning Week 6 NPTEL Assignment Answers. These expert-verified solutions are designed to help you understand key concepts, simplify complex topics, and enhance your assignment performance. Stay tuned for weekly updates and visit www.answergpt.in for the most accurate and detailed solutions.

